(記者陳光蘊/台北報導)Meta今發表 AI 技術的重大突破,其「絕不拋下任何語言」專案 ( No Language Left Behind,簡稱NLLB ) 已打造出NLLB-200 AI模型,是全球第一個能翻譯200種不同語言的單一AI模型,將為超過十億人提供高品質翻譯內容。NLLB-200將促進使用不同語言的社群間更多元的交流,研究成果將支援Facebook動態消息、Instagram及其他平台上高達250億則翻譯內容,讓大家只要點擊一個按鈕就可以用自己熟悉的語言準確了解內容。同時,為了協助其他研究人員改善翻譯工具,並在基礎上打造更優質的翻譯系統,Meta 釋出開源內容包含:NLLB-200 模型、FLORES-200、模型訓練程式碼以及用於重建訓練資料集的程式碼。
語言是人們在世界上展現文化、身分的工具,但因為沒有可以翻譯上百種語言的高品質翻譯工具,現今世界上有數十億人,無法透過他們慣用的語言或母語讀取網路上的內容或者完整參與社群上的討論,尤其是在非洲與亞洲等地區有高達數億人使用眾多不同的語言,這樣的狀況特別明顯。為協助網路社群突破語言隔閡,並促進元宇宙未來發展,Meta AI 研究人員已成立NLLB 專案,為全世界大多數語言提供高品質的翻譯功能。目前 Meta NLLB-200 AI模型已可翻譯200種不同的語言,包括許多目前翻譯工具無法支援的非洲語言及其他少數語言,翻譯品質更較現有翻譯工具平均提升了44%。Meta 更與維基媒體基金會(Wikimedia Foundation)合作,透過 NLLB-200 協助改善維基百科的翻譯系統,並開放 NLLB-200 原始碼讓其他研究人員可以將此研究擴大至更多語言,打造更具包容性的技術。
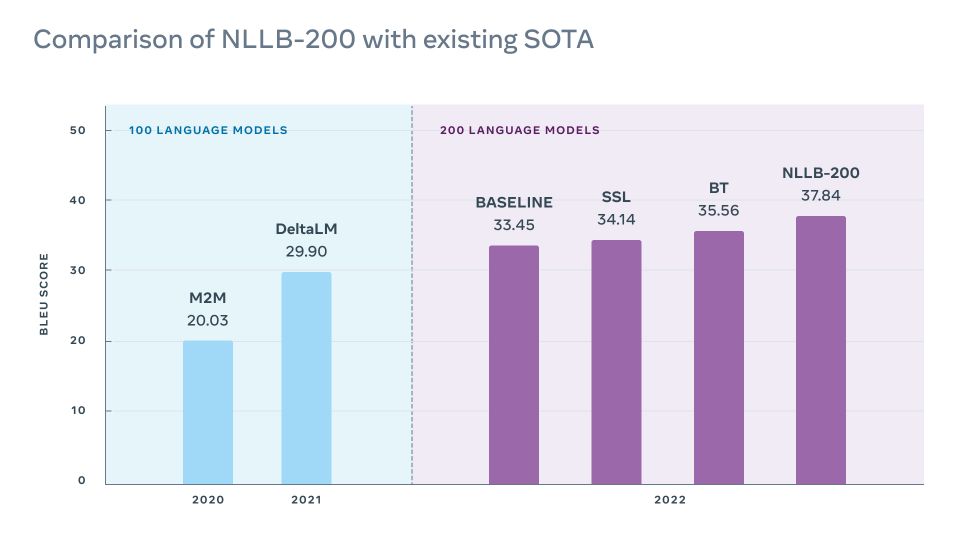
透過 AI 翻譯內容對民眾日常生活影響甚鉅,NLLB不只能讓大家更容易獲取網路上的內容,也可以讓不同語言的用戶貢獻並分享資訊。未來NLLB研究成果將支援Facebook動態消息、Instagram和 Meta 其他平台上每天所提供超過250億則的翻譯內容,大家在網路瀏覽不同語言的社群內容時,只要點擊一個按鈕就可透過自己的語言準確了解網路上的資訊。不只應用在數位世界中,Meta AI 也為非營利組織提供20萬美元的補助金,推廣 NLLB-200 在實體世界的應用。為了精進 NLLB-200 模型,Meta建立了獨特的多對多評估資料集 FLORES-200,讓研究人員可以評估NLLB-200在各語言中的運作成效,確保提供高品質的翻譯內容。在多項指標中,相較於現有的其他翻譯工具,NLLB-200 的平均品質高出 44%。在部分非洲和印度語言中,提升幅度相較最新的翻譯系統更提升了 70%。為了協助其他研究人員迅速測試及改善其翻譯模型,同時,Meta開放 NLLB-200 模型的原始碼並發佈一系列研究工具,讓其他研究人員將此工作擴大至更多語言,以及打造更具包容性的技術。
為了確保 Meta 以負責任的方式發展此項計畫,Meta 與語言學家、社會學家、倫理學家等跨學科團隊合作,深入了解各種語言。此外,為管理因翻譯擴大至 200 種語言而衍生的負面內容的風險, Meta 對所有支援的語言建立了負面內容清單,以便偵測篩選出褻瀆性詞語或可能具有冒犯性的內容,同時將此清單分享給其他研究人員,以降低研究人員在建置模型中的風險。